singleflight 是 Go 官方扩展库 x 中提供的扩展并发原语,能够将多个并发请求合并为一个,降低服务端压力。本文就来介绍下它的用法和实现原理。
请求合并
singleflight 主要用于抑制重复的并发调用,从而避免对同一资源进行重复操作,提升系统性能。
比如,当我们有多个 goroutine 并发调用一个同一个函数时,singleflight 能够实现只让一个 goroutine 发起调用,其他 goroutine 则阻塞等待,当发起调用的 goroutine 返回后,singleflight 将结果同时返回给所有 goroutine。这样我们就减少了大量的并发调用,避免重复操作。
这也是 singleflight 提供的唯一能力——请求合并。
在 Go 后端开发中,我们很容易想到,高并发场景下缓存失效时大量请求落到 DB 的场景,正是 singleflight 的用武之地。
如下图所示:
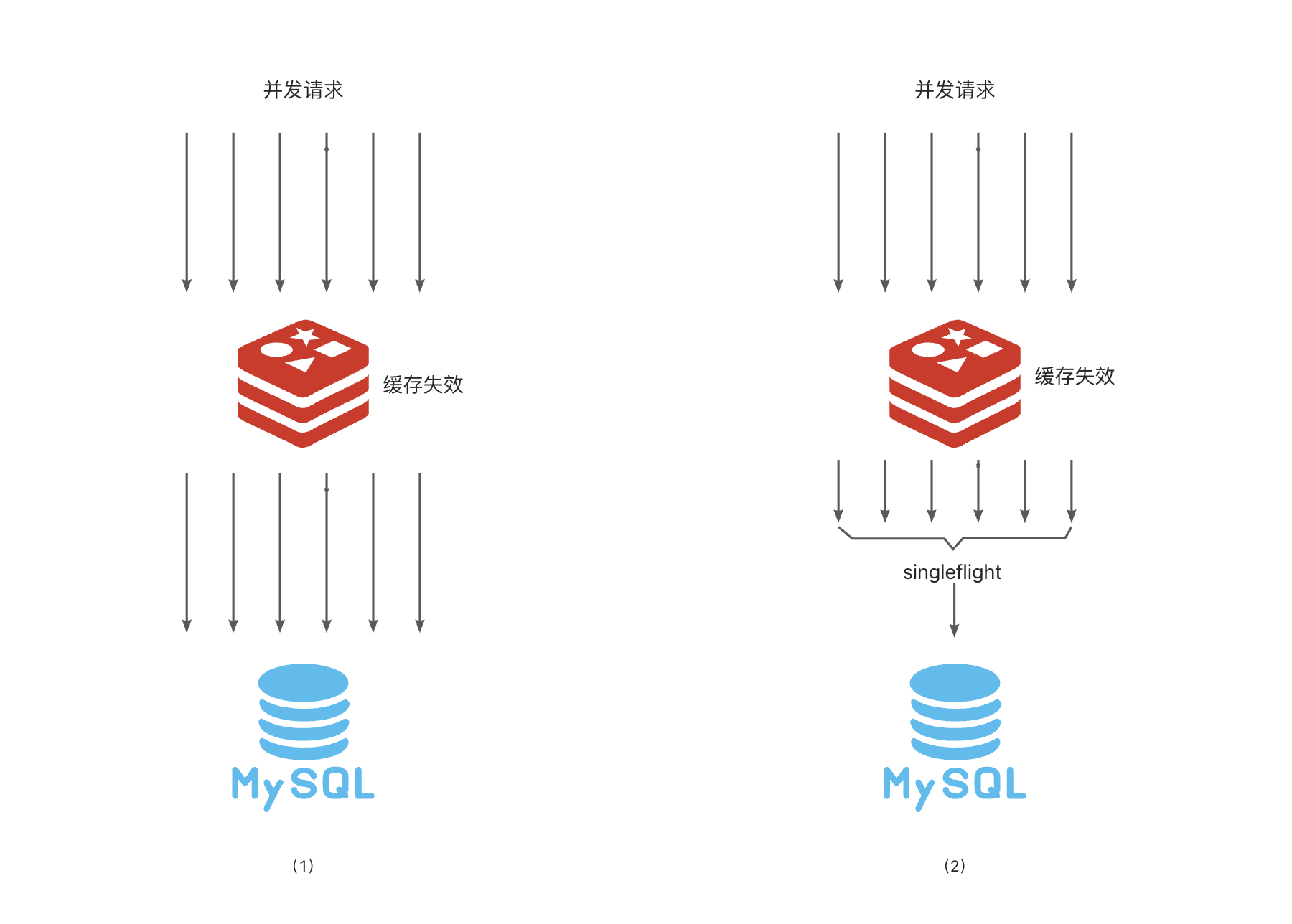
左侧图(1)中,当大量请求过来读取 Redis 缓存时,它们同时发现缓存失效,那么所有请求都会继续向下请求 MySQL 读取数据。
右侧图(2)中,当所有请求都去 MySQL 读取数据时,我们可以使用 singleflight 合并这些请求,只保留一个请求去调用 MySQL 读取数据,然后将结果返回给所有请求。
这就是 singleflight 的典型应用场景。
现在,请你思考下 singleflight 和 sync.Once 有什么区别呢?我会在后文中揭晓答案。
NOTE:
如果你对
sync.Once不熟悉,可以阅读我的另一篇文章《Go 并发控制:sync.Once 详解》。
SingleFlight 使用示例
知道了 singleflight 作用,想必你已经跃跃欲试要动手实践了。废话不多说,咱们直接看效果。
singleflight 使用示例代码如下:
1 | package main |
简单解释下这个示例程序,我们想要模拟的就是高并发场景下缓存失效时大量请求落到 DB 的场景。
在 main 函数中,首先声明了 sync.WaitGroup 变量来控制并发,keys 表示我们要并发查询的用户,这里以 username 作为查询的 key。接着遍历这些 keys 并开启新的 goroutine 来并发的查询 User 信息。
GetUser 会先尝试从缓存读取数据,若没有命中,再去数据库中查询。从数据库获取数据需要调用 GetUserFromDB 函数,不过 GetUser 中并没有直接去调用它,而是使用 singleflight 实例对象 requestGroup.Do 方法来调用。Do 方法接收两个参数,一个字符串类型的 key 和一个函数 fn,对于同一个 key,在并发情况下,只有一个 fn 正在执行。而 requestGroup.Do 返回的 result 就是函数 fn 的第一个返回值。在函数 fn 内部调用了 GetUserFromDB 并将从 DB 查询到的数据存入缓存 cache 中。
我们在 main 函数中共发起了两轮并发查询用户信息的请求。第一轮时,缓存 cache 为空,所以请求会落在 DB,第二轮时,缓存 cache 中有数据,所以请求直接读取缓存,不会查询 DB。
执行示例代码,得到如下输出:
1 | $ go run main.go |
可以发现,第一轮并发请求中,fmt.Printf("User %s not in cache\n", key) 的日志打印了 3 次,说明缓存确实为空。fmt.Printf("Querying DB for key: %s\n", username) 日志打印了 2 次,说明 singleflight 生效了,因为 3 个并发请求中,有 2 个 key 是一样的 user_123,所以 singleflight 合并了请求。
第二轮并发请求发起时,缓存中已经存在数据,所以只会打印 fmt.Printf("Get user for key: %s -> %+v\n", k, GetUser(k)) 的日志信息。
现在你应该对 singleflight 有一个比较直观的认识了。不过,我在这里讲解的并不够详细,如果完全没接触过 singleflight 这个概念,可能会有一些疑惑。没关系,接下来我将对 singleflight 源码进行讲解,相信看过源码后,你心中的疑惑就都能解开了。毕竟,源码之下无秘密。
SingleFlight 源码解析
singleflight 源码中有两个核心结构体:
1 | // call is an in-flight or completed singleflight.Do call |
其中 Group 代表 singleflight 对象,它有两个字段,mu 是一个互斥锁,用于保护 m 的并发访问。m 是一个 map,会被延迟初始化,m 的键就是调用 singleflight.Do 时传递的第一个参数 key,m 的值是一个 *call 对象。
call 代表一个正在执行(in-flight)或已完成(completed)的 fn 函数的调用,也就是说,它会记录我们在调用 singleflight.Do 时传递的第二个参数 fn 的完整生命周期。
Group 对象提供了三个公有方法,签名如下:
1 | func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) |
Do方法我们见过了,它接收一个key和一个函数fn,对于同一个key,在并发情况下,只有一个fn正在执行,其他请求会阻塞等待。函数fn无参数,有两个返回值value和error。当fn执行完成并返回,Do方法会返回fn的执行结果value和error,即Do方法返回值的前两个。而Do方法的最后一个返回值shared,则表示返回值v是否共享给了多给调用方,即在fn执行时,有其他并发请求过来,不过它们并没有真正执行,而是等待这个fn的返回结果。DoChan方法其实和Do方法类似,只不过返回值变成了一个channel。并发情况下对DoChan的调用不会阻塞等待第一个fn执行完成,而是直接返回channel,等fn执行完成后,会将结果Result通过这个channel返回。Forget告知Group忘记一个key,在调用Forget之后,再次调用Do/DoChan方法将不再等待前一个未完成的fn执行结果,而是当作一个新的请求来处理。
DoChan 方法的返回值中的 Result 类型,其实就是对 Do 方法返回的三个值的封装,方便在 channel 中传递。
Result 类型定义如下:
1 | // Result holds the results of Do, so they can be passed |
现在我们对 Group 对象提供的三个方法源码依次进行讲解。
singleflight.Do
我们先看 Do 方法的实现:
1 | func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) { |
Do 方法内部首先会进行加锁操作,保证所有对 m 的操作并发安全。
Group 对象的 m 属性延迟到调用 Do 方法时才被初始化,所以 Group 对象其实无需实例化即可直接使用。
如果 key 不在 m 中,说明是这个 key 的第一个请求,会为其创建一个 call 对象,并保存到 m 中。然后就交给 Group.doCall 来处理 fn 的调用了。并且 call 对象使用了 sync.WaitGroup 来控制并发调用。
如果 key 在 m 中,则说明不是这个 key 的第一个请求,那么就可以调用 c.wg.Wait() 等待第一个请求完成,然后直接从 call 对象的 val 和 err 属性中拿到 fn 的返回值。在这里并没执行当前请求的 fn,call 对象上的结果是当前 key 的第一个请求返回的,所以就实现了类似“缓存”的效果,有效合并了多次请求调用。
此外,在这里有两处错误类型判断,c.err.(*panicError) 和 c.err == errGoexit。
其中 panicError 定义如下:
1 | type panicError struct { |
当同一个 key 的第一个请求函数 fn 调用发生了 panic,就会在 c.err 中保存一个 *panicError 对象,那么后续的并发请求过来,也要重新触发 panic。
另一个错误 errGoexit 定义如下:
1 | var errGoexit = errors.New("runtime.Goexit was called") |
这是一个典型的 Sentinel error,用于标记在用户提供的 fn 函数内部调用了 runtime.Goexit() 来退出 goroutine,后续的并发请求过来,也要重新调用 runtime.Goexit()。
NOTE:
runtime.Goexit用于终止当前 goroutine(其他正在运行的协程不受影响,程序继续正常运行),不会继续执行后续代码。并且在退出前会执行当前 goroutine 的所有defer语句,确保资源被正确释放。此外runtime.Goexit()不会引发panic,因此无法通过recover捕获。
那么现在 Do 方法的工作流程就清晰了:
- 请求
Do(key, fn) (v, err, shared)被调用- 如果
key不存在:创建一个新的call,执行用户函数fn。 - 如果
key已存在:等待现有操作fn调用完成,复用其结果。
- 如果
fn函数完成后- 直接返回
fn的执行结果。 - 或者唤醒等待的重复请求,返回
fn的执行结果。
- 直接返回
singleflight.DoChan
接下来再看 DoChan 方法的实现:
1 | func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result { |
可以发现,DoChan 方法的内部逻辑与 Do 方法类似,只不过它不会阻塞等待第一个请求执行完成,而是启动新的 goroutine 调用 doCall 来执行 fn,并返回一个 channel 对象。
那么也就是说,Do 方法和 DoChan 方法的核心逻辑其实都是在 doCall 方法中了。
singleflight.doCall
doCall 方法的实现:
1 | func (g *Group) doCall(c *call, key string, fn func() (interface{}, error)) { |
这个方法有点长,不过整体脉络是清晰的,我们拆成几个小的逻辑代码段来分析它。
函数在最开始处初始化两个变量:
1 | normalReturn := false |
normalReturn 如果为 true,则说明 fn 正常返回。
recovered 如果为 true,则说明 fn 执行期间发生了 panic。
然后是一大段延迟执行的 defer 语句,我们先跳过它,直接来看下面的匿名立即执行函数逻辑:
1 | func() { |
这里之所以使用一个立即执行函数,是为了执行 defer 语句。函数内主要逻辑就是调用 fn 函数,并将其结果保存到 *call 对象 c.val 和 c.err 两个属性中。
fn 执行成功,则标记 normalReturn 为 true,表明 fn 正常返回,执行期间没有发生 panic 或调用 runtime.Goexit()。
如果 fn 内发生 panic,则会被 defer 中的 recover 捕获到,并使用 panic 信息创建一个 *panicError 对象保存到 c.err 属性中。
newPanicError 函数实现如下:
1 | func newPanicError(v interface{}) error { |
这里代码很简单,使用 debug.Stack() 获取当前 goroutine 的调用栈信息,然后截掉第一行 goroutine N [status]: 格式的堆栈内容,再构造一个 *panicError 对象并返回。
NOTE:
debug.Stack是对runtime.Stack的一个高层次的封装,直接返回当前 goroutine 的调用栈信息。
回忆下在 Do 函数中有一个错误类型断言 c.err.(*panicError),错误信息就是在这里通过调用 newPanicError 创建并赋值给 c.err 的。
匿名函数执行完成后,代码逻辑走到这里:
1 | if !normalReturn { |
如果此时 normalReturn 为 false,则执行 fn 时必然出现了 panic,所以记录 recovered 值为 true。
这里之所以能这样断定 fn 中出现 panic,是因为这段逻辑与匿名的立即执行函数在同一个 goroutine 中,如果 c.val, c.err = fn() 这行执行成功,内部肯定没有发生 panic 或调用 runtime.Goexit(),那么 normalReturn = true 也必然会执行成功。而如果 normalReturn 为 false,则有可能发生 panic 或调用 runtime.Goexit()。但是如果调用 runtime.Goexit(),那么当前 goroutine 会立即终止,所以代码根本就不会执行到此处。既然代码能够执行到此处,且 normalReturn 为 false,就只剩一种可能,fn 中发生了 panic。
doCall 方法最后一行代码已经执行完成,接下来就要执行到顶部的 defer 函数中了:
1 | // 使用 double-defer 来区分 panic 或 runtime.Goexit |
在 defer 函数中首先对 fn 函数的执行结果进行了判断,如果没有正常退出,且未发生 panic,则说明一定是调用了 runtime.Goexit()。
所以,这也是为什么 doCall 方法中共计使用了两个 defer 语句,就是为了对 fn 的三种可能执行结果进行判别。
c.wg.Done() 通知阻塞等待的其他请求可以获取 fn 函数的执行结果了。
当 fn 执行完成,立即从 Group.m 中删除 fn 函数所对应的 key。所以,singleflight 只保证并发情况下,合并多个请求。如果这一轮并发结束,下次相同 key 发来的请求,fn 函数会依然会执行。所以看到此处,我想你应该能 Get 到 singleflight 与 sync.Once 的不同之处了。
接下来的逻辑就有点意思了,如果 c.err 中记录的 error 是 *panicError 类型,则说明 fn 函数发生了 panic。那么此时需要重新触发 panic,让调用方感知到。这又分两种情况,如果 len(c.chans) > 0 成立,则说明用户调用了 DoChan 方法,此时为了防止调用方用来等待 channel 的 goroutine 被永久阻塞,需要确保这个 panic 不能被 recover,所以启动了一个新的 goroutine 来执行 panic(e),select {} 则是用来保持当前 goroutine 不被退出。另一种情况则是用户调用了 Do 方法,那么直接执行 panic(e) 即可。
NOTE:
recover只能捕获当前 goroutine 中的panic,我在另一篇文章《Go 错误处理指北:Defer、Panic、Recover 三剑客》中进行了详细讲解。
如果 c.err == errGoexit 成立,则说明 fn 函数内容调用了 runtime.Goexit(),那么无需特殊处理,当前 goroutine 会继续执行退出操作。
最终代码进入 else 逻辑,说明 fn 正常返回,如果用户调用了 DoChan 方法,则 c.chans 有值,将 fn 执行结果包装成 Result 并通过 channel 通知给所有等待者。
至此,singleflight 最核心的方法 doCall 就执行完成了。
我们来梳理下 doCall 方法的工作流程:
- 调用
fn函数,执行fn的逻辑包裹在嵌套的匿名函数中,并处理可能产生的panic或runtime.Goexit。 - 处理返回结果,在
defer方法中,区分了fn函数的正常返回、panic和runtime.Goexit三种可能执行结果,并设置对应的状态和错误信息。 - 分发
fn函数的执行结果或错误信息,如果用户调用了Do方法,可以从*call对象的c.val和c.err两个属性中拿到结果,如果用户调用了DoChan方法,最终会将结果广播到所有等待的channel。
doCall 方法代码量不大,不过其中中有两处关键点值得注意:
- 双层
defer设计(double-defer)- 第一层
defer用于捕获panic。 - 第二层
defer则用于处理runtime.Goexit和资源释放。
- 第一层
- 对于
panic的处理*panicError中包含了错误值和堆栈信息,便于调试。- 通过 goroutine 执行
panic(e)保证不会阻塞等待channel的调用者。
singleflight.Forget
现在还剩下最后方法没有分析了,Forget 方法源码如下:
1 | func (g *Group) Forget(key string) { |
一目了然,Forget 方法用于调用方主动告知 Group 忘记一个 key。
Forget 方法适用场景如下:
- 长时间未完成的调用,比如某个函数执行时间过长,但业务上已经不再需要结果,此时可以通过
Forget主动移除key。 - 错误请求的清理,如果某次调用由于逻辑错误进入了无效状态,直接
Forget该调用,可以避免fn执行结果后续被误用。 - 重试机制,在某些场景下,你希望对同一个
key发起新的调用,而不是复用之前的结果。
不过,还是建议慎使用 Forget,有需要时再使用。因为如果调用时间较短且结果重要,频繁使用 Forget 可能导致资源浪费,singleflight 也就失去了意义。
SingleFlight 适用场景
现在我们对 singleflight 的源码进行了解析,那么 singleflight 的适用场景也就清晰了。
singleflight 典型使用场景如下:
- 缓存击穿
- 问题: 缓存中的某个热点键过期,导致大量请求同时访问后端数据库,增加系统压力。
- 解决: 使用
singleflight确保在缓存重建过程中,只有一个请求会访问数据库,其他请求等待结果返回。
- 远程服务调用
- 问题: 多个并发请求访问同一个远程服务时,可能造成不必要的重复调用,浪费带宽和计算资源。
- 解决: 使用
singleflight使相同的请求合并为一次。
- 定时任务去重
- 问题: 在分布式系统中,多个节点可能同时执行定时任务,导致重复任务执行。
- 解决: 使用
singleflight确保只有一个节点执行任务,其他节点共享结果。
- 消息去重
- 问题: 消息队列中可能存在重复消息的消费问题。
- 解决: 在消费端使用
singleflight,确保对相同消息的处理只执行一次。
- 分布式锁优化
- 问题: 多个节点同时抢锁时,可能会发起大量重复的加锁尝试。
- 解决: 使用
singleflight降低对分布式锁的访问压力,只允许一个请求实际去尝试加锁。
SingleFlight 的核心作用是抑制重复的并发调用,在并发场景中,多次相同请求(由同一个 key 标识)过来时,让它们共享第一个调用的结果,而不是重复执行。这在读操作中尤其常见,而对于写操作,合并的需求和行为需要更慎重的对待。
关于 SingleFlight 你认为还有那些使用场景可以分享出来,大家一起探讨学习。
总结
singleflight 主要用于抑制重复的并发调用,从而避免对同一资源进行重复操作,提升系统性能。所以 singleflight 适用于可以合并请求的操作。
singleflight 提供了三个公有方法 Do、DoChan 和 Forget,Do 和 DoChan 两个方法作用相同都用来合并请求,二者的核心逻辑在 doCall 方法中。Forget 方法则用于调用方主动告知 Group 忘记一个 key。
singleflight 典型使用场景有缓存击穿、远程服务调用、任务去重、消息去重、分布式锁优化等。
我在前文中留过一个思考题,singleflight 和 sync.Once 有什么区别,现在你有答案了吗?
singleflight 只用在并发场景下,同时有多个重复的请求,才能够合并请求。而当请求结束,就会执行 delete(g.m, key) 删除 key,下一次请求过来 fn 依然被重新执行。
sync.Once 则始终保证函数 f 只被调用一次。
二者虽然看起来功能类似,但它们的实现原理和适用场景各不相同。
此外,其实在 Go 源码中的 internal 包下,也有一个 SingleFlight 的实现,与扩展库 x 中的实现思路相同,代码更加简单,感兴趣的读者可以跳转过去查看其源码实现。
本文示例源码我都放在了 GitHub 中,欢迎点击查看。
希望此文能对你有所启发。
延伸阅读
- Go Wiki: X-Repositories:https://go.dev/wiki/X-Repositories
- singleflight Documentation:https://pkg.go.dev/golang.org/x/sync@v0.9.0/singleflight
- singleflight GitHub 源码:https://github.com/golang/sync/tree/v0.9.0/singleflight
- Go 源码中 internal 包下的 singleflight:https://github.com/golang/go/tree/go1.23.0/src/internal/singleflight
- Go 并发控制:sync.Once 详解:https://jianghushinian.cn/2024/11/11/sync-once/
- Go 错误处理指北:Defer、Panic、Recover 三剑客:https://jianghushinian.cn/2024/10/13/go-error-guidelines-defer-panic-recover/
- 本文 GitHub 示例代码:https://github.com/jianghushinian/blog-go-example/tree/main/x/sync/singleflight
联系我
- 公众号:Go编程世界
- 微信:jianghushinian
- 邮箱:jianghushinian007@outlook.com
- 博客:https://jianghushinian.cn
- GitHub:https://github.com/jianghushinian