GORM 是 Go 语言中最受欢迎的 ORM 库之一,它提供了强大的功能和简洁的 API,让数据库操作变得更加简单和易维护。本文将详细介绍 GORM 的常见用法,包括数据库连接、模型定义、CRUD、事务管理等方面,帮助大家快速上手使用 GORM 进行 Web 后端开发。
安装
通过如下命令安装 GORM:
1 | $ go get -u gorm.io/gorm |
你也许见过使用 go get -u github.com/jinzhu/gorm 命令来安装 GORM,这个是老版本 v1,现已过时,不建议使用。新版本 v2 已经迁移至 github.com/go-gorm/gorm 仓库下。
快速开始
如下示例代码带你快速上手 GORM 的使用:
1 | package main |
提示:这里使用了
SQLite数据库驱动,需要通过go get -u gorm.io/driver/sqlite命令安装。
将以上代码保存在 main.go 中并执行。
1 | $ go run main.go |
执行完成后,我们将在当前目录下得到 test.db SQLite 数据库文件。
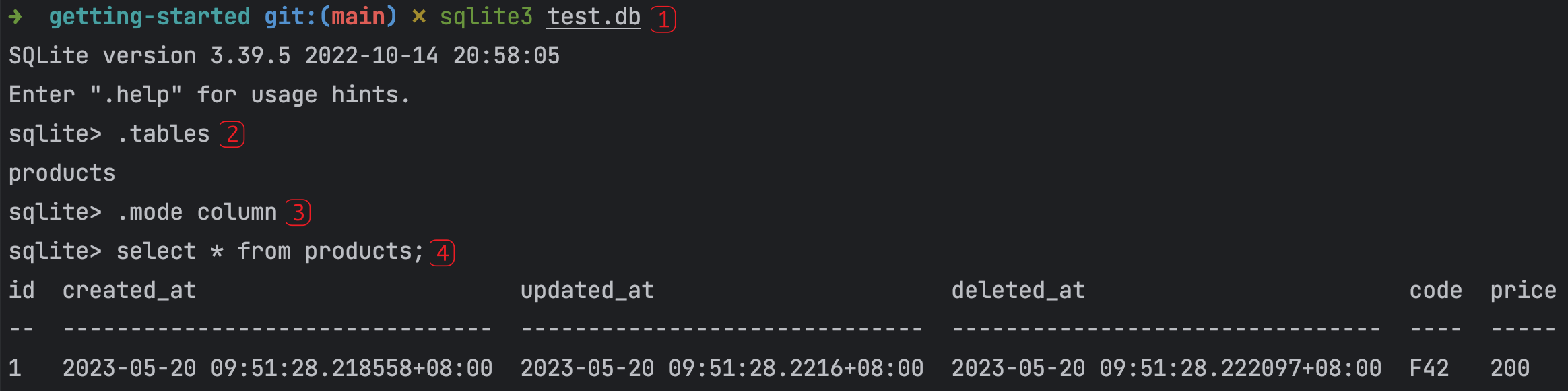
① 进入 SQLite 命令行。
② 查看已存在的数据库表。
③ 设置稍后查询表数据时的输出模式为按列左对齐。
④ 查询表中存在的数据。
有过使用 ORM 框架经验的同学,以上代码即使我不进行讲解也能看懂个大概。
这段示例代码基本能够概括 GORM 框架使用套路:
定义结构体映射表结构:
Product结构体在 GORM 中称作「模型」,一个模型对应一张数据库表,一个结构体实例对象对应一条数据库表记录。连接数据库:GORM 使用
gorm.Open方法与数据库建立连接,连接建立好后,才能对数据库进行 CRUD 操作。自动迁移表结构:调用
db.AutoMigrate方法能够自动完成在数据库中创建Product结构体所映射的数据库表,并且,当Product结构体字段有变更,再次执行迁移代码,GORM 会自动对表结构进行调整,非常方便。不过,我不推荐在生产环境项目中使用此功能。因为数据库表操作都是高风险操作,一定要经过多人 Review 并审核通过,才能执行操作。GORM 自动迁移功能虽然理论上不会出现问题,但线上操作谨慎为妙,个人认为只有在小项目或数据不那么重要的项目中使用比较合适。CRUD 操作:迁移好数据库后,就有了数据库表,可以进行 CRUD 操作了。
有些同学可能有个疑问,以上示例代码中并没有类似 defer db.Close() 主动关闭连接的操作,那么何时关闭数据库连接?
其实 GORM 维护了一个数据库连接池,初始化 db 后所有的连接都由底层库来管理,无需程序员手动干预,GORM 会在合适的时机自动关闭连接。GORM 框架作者 jinzhu 也有在源码仓库 Issue 中回复过网友的提问,感兴趣的同学可以点击进入查看。
接下来我将对 GORM 的使用进行详细讲解。
声明模型
GORM 使用模型(Model)来映射一张数据库表,模型是标准的 Go struct,由 Go 的基本数据类型、实现了 Scanner 和 Valuer 接口的自定义类型及其指针或别名组成。
例如:
1 | type User struct { |
我们可以使用 gorm 字段标签来控制数据库表字段的类型、列大小、默认值等属性,比如使用 column 字段标签来映射数据库中字段名称。
1 | type User struct { |
在不指定 column 字段标签情况下,GORM 默认使用字段名的 snake_case 作为列名。
GORM 默认使用结构体名的 snake_cases 作为表名,为结构体实现 TableName 方法可以自定义表名。
我更喜欢「显式胜于隐式」的做法,所以数据库名和表名都会显示写出来。
因为我们不使用自动迁移的功能,所以其他字段标签都用不到,就不在此一一介绍了,感兴趣的同学可以查看官方文档进行学习。
User 结构体中有一个嵌套的结构体 gorm.Model,它是 GORM 默认提供的一个模型 struct,用来简化用户模型定义。
GORM 倾向于约定优于配置,默认情况下,使用 ID 作为主键,使用 CreatedAt、UpdatedAt、DeletedAt 字段追踪记录的创建、更新、删除时间。而这几个字段就定义在 gorm.Model 中:
1 | type Model struct { |
由于我们不使用自动迁移功能,所以需要手动编写 SQL 语句来创建 user 数据库表结构:
1 | CREATE TABLE `user` ( |
数据库中字段类型要跟 Go 中模型的字段类型相对应,不兼容的类型可能导致错误。
连接数据库
GORM 官方支持的数据库类型有:MySQL、PostgreSQL、SQLite、SQL Server 和 TiDB。
这里使用最常见的 MySQL 作为示例,来讲解 GORM 如何连接到数据库。
在前文快速开始的示例代码中,我们使用 SQLite 数据库时,安装了 sqlite 驱动程序。要连接 MySQL 则需要使用 mysql 驱动。
在 GORM 中定义了 gorm.Dialector 接口来规范数据库连接操作,实现了此接口的程序我们将其称为「驱动」。针对每种数据库,都有对应的驱动,驱动是独立于 GORM 库的,需要单独引入。
连接 MySQL 数据库的代码如下:
1 | package main |
可以发现,这段代码与连接 SQLite 数据库的代码如出一辙,这就是面向接口编程的好处。
首先,mysql.Open 接收一个字符串 dsn,DSN 全称 Data Source Name,翻译过来叫数据库源名称。DSN 定义了一个数据库的连接信息,包含用户名、密码、数据库 IP、数据库端口、数据库字符集、数据库时区等信息。DSN 遵循特定格式:
1 | username:password@protocol(address)/dbname?param=value |
通过 DSN 所包含的信息,mysql 驱动就能够知道以什么方式连接到 MySQL 数据库了。
mysql.Open 返回的正是一个 gorm.Dialector 对象,将其传递给 gorm.Open 方法后,我们将得到 *gorm.DB 对象,这个对象可以用来操作数据库。
GORM 使用 database/sql 来维护数据库连接池,对于连接池我们可以设置如下几个参数:
1 | func SetConnect(db *gorm.DB) error { |
现在,数据库连接已经建立,我们可以对数据库进行操作了。
创建
可以使用 Create 方法创建一条数据库记录:
1 | now := time.Now() |
要创建记录,我们需要先实例化 User 对象,然后将其指针传递给 db.Create 方法。
db.Create 方法执行完成后,依然返回一个 *gorm.DB 对象。
user.ID 会被自动填充为创建数据库记录后返回的真实值。
result.RowsAffected 可以拿到此次操作影响行数。
result.Error 可以知道执行 SQL 是否出错。
在这里,我将 db.Create(&user) 这句 ORM 代码所生成的原生 SQL 语句放在了注释中,方便你对比学习。并且,之后的示例中我也会这样做。
Create 方法不仅支持创建单条记录,它同样支持批量操作,一次创建多条记录:
1 | now = time.Now() |
代码主要逻辑不变,只需要将单个的 User 实例换成 User 切片即可。GORM 会使用一条 SQL 语句完成批量创建记录。
查询
查询记录是我们在日常开发中使用最多的场景了,GORM 提供了多种方法来支持 SQL 查询操作。
使用 First 方法可以查询第一条记录:
1 | var user User |
First 方法接收一个模型指针,通过模型的 TableName 方法则可以拿到数据库表名,然后使用 SELECT * 语句从数据库中查询记录。
根据生成的 SQL 可以发现 First 方法查询数据默认根据主键 ID 升序排序,并且只会过滤删除时间为 NULL 的数据,使用 LIMIT 关键字来限制数据条数。
使用 Last 方法可以查询最后一条数据,排序规则为主键 ID 降序:
1 | var lastUser User |
使用 Where 方法可以增加查询条件:
1 | var users []User |
这里不再查询单条数据,所以改用 Find 方法来查询所有符合条件的记录。
以上介绍的几种查询方法,都是通过 SELECT * 查询数据库表中的全部字段,我们可以使用 Select 方法指定需要查询的字段:
1 | var user2 User |
使用 Order 方法可以自定义排序规则:
1 | var users2 []User |
GORM 也提供了对 Limit & Offset 的支持:
1 | var users3 []User |
使用 -1 可以取消 Limit & Offset 的限制条件:
1 | var users4 []User |
这段代码会执行两条查询语句,之所以能够采用这种「链式调用」的方式执行多条 SQL,是因为每个方法返回的都是 *gorm.DB 对象,这也是一种编程技巧。
使用 Count 方法可以统计记录条数:
1 | var count int64 |
有时候遇到比较复杂的业务,我们可能需要使用 SQL 子查询,子查询可以嵌套在另一个查询中,GORM 允许将 *gorm.DB 对象作为参数时生成子查询:
1 | var avgages []float64 |
Having 方法签名如下:
1 | func (db *DB) Having(query interface{}, args ...interface{}) (tx *DB) |
第二个参数是一个范型 interface{},所以不仅可以接收字符串,GORM 在判断其类型为 *gorm.DB 时,就会构造一个子查询。
更新
为了讲解更新操作,我们需要先查询一条记录,之后的更新操作都是基于这条被查询出来的 User 对象:
1 | var user User |
更新操作只要修改 User 对象的属性,然后调用 db.Save(&user) 方法即可完成:
1 | user.Name = "John" |
在更新操作时,User 对象要保证 ID 属性存在值,不然就变成了创建操作。
Save 方法会保存所有的字段,即使字段是对应类型的零值。
除了使用 Save 方法更新所有字段,我们还可以使用 Update 方法更新指定字段:
1 | // UPDATE `user` SET `name`='Jianghushinian',`updated_at`='2023-05-22 22:24:34.215' WHERE `user`.`deleted_at` IS NULL AND `id` = 1 |
Update 只能支持更新单个字段,要想更新多个字段,可以使用 Updates 方法:
1 | // UPDATE `user` SET `updated_at`='2023-05-22 22:29:35.19',`name`='JiangHu' WHERE `user`.`deleted_at` IS NULL AND `id` = 1 |
注意,Updates 方法与 Save 方法有一个很大的不同之处,它只会更新非零值字段。Age 字段为零值,所以不会被更新。
如果一定要更新零值字段,除了可以使用上面的 Save 方法,还可以将 User 结构体换成 map[string]interface{} 类型的 map 对象:
1 | // UPDATE `user` SET `age`=0,`name`='JiangHu',`updated_at`='2023-05-22 22:29:35.623' WHERE `user`.`deleted_at` IS NULL AND `id` = 1 |
此外,更新数据时,还可以使用 gorm.Expr 来实现 SQL 表达式:
1 | // UPDATE `user` SET `age`=age + 1,`updated_at`='2023-05-22 22:24:34.219' WHERE `user`.`deleted_at` IS NULL AND `id` = 1 |
gorm.Expr("age + ?", 1) 方法调用会被转换成 age=age + 1 SQL 表达式。
删除
可以使用 Delete 方法删除数记录:
1 | var user User |
对于删除操作,GORM 默认使用逻辑删除策略,不会对记录进行物理删除。
所以 Delete 方法在对数据进行删除时,实际上执行的是 SQL UPDATE 操作,而非 DELETE 操作。
将 deleted_at 字段更新为当前时间,表示当前数据已删除。这也是为什么前文在讲解查询和更新的时候,生成的 SQL 语句都自动附加了 deleted_at IS NULL Where 条件的原因。
这样就实现了逻辑层面的删除,数据在数据库中仍然存在,但查询和更新的时候会将其过滤掉。
记录被删除后,我们无法通过如下代码直接查询到被逻辑删除的记录:
1 | // SELECT * FROM `user` WHERE name = 'JiangHu' AND `user`.`deleted_at` IS NULL ORDER BY `user`.`id` LIMIT 1 |
这将得到一个错误 record not found。
不过,GORM 提供了 Unscoped 方法,可以绕过逻辑删除:
1 | // SELECT * FROM `user` WHERE name = 'JiangHu' ORDER BY `user`.`id` LIMIT 1 |
以上代码能够查询出被逻辑删除的记录,生成的 SQL 语句中没有包含 deleted_at IS NULL Where 条件。
对于比较重要的数据,建议使用逻辑删除,这样可以在需要的时候恢复数据,也便于故障追踪。
不过,如果明确想要物理删除一条记录,同理可以使用 Unscoped 方法:
1 | // DELETE FROM `user` WHERE name = 'JiangHu' AND `user`.`id` = 1 |
关联
日常开发中,多数情况下不只是对单表进行操作,还要对存在关联关系的多表进行操作。
这里以一个博客系统最常见的三张表「文章表、评论表、标签表」为例,对 GORM 如何操作关联表进行讲解。
这里涉及最常见的关联关系:一对多和多对多。一篇文章可以有多条评论,所以文章和评论是一对多关系;一篇文章可以存在多个标签,每个标签也可以包含多篇文章,所以文章和标签是多对多关系。
模型定义如下:
1 |
|
我准备了对应的建表 SQL,可以点击链接进行查看:GitHub 地址。
在模型定义中,Post 文章模型使用 Comments 和 Tags 分别保存关联的评论和标签,这两个字段不会保存在数据库表中。
Comments 字段标签使用 foreignKey 来指明 Comments 表中的外键,并使用 constraint 指明了约束条件,references 指明 Comments 表外键引用 Post 表的 ID 字段。
其实现在生产环境中都不再推荐使用外键,各个表之间不再有数据库层面的外键约束,在做 CRUD 操作时全部通过代码层面来进行业务约束。这里为了演示 GORM 的外键和级联操作功能,所以定义了这些结构体标签。
Tags 字段标签使用 many2many 来指明多对多关联表名。
对于 Comment 模型,PostID 字段就是外键,用来保存 Post.ID。Post 字段同样不会保存在数据库中,这种做法在 ORM 框架中非常常见。
接下来,我将同样对关联表的 CRUD 操作进行一一讲解。
创建
创建 Post 时会自动创建与之关联的 Comments 和 Tags:
1 | var post Post |
这里定义了一个文章对象 post,并且包含两条评论和两个标签。
注意 Comment 的 Post 字段引用了 &post,并没有指定 PostID 外键字段,GORM 能够正确处理它。
以上代码将生成并依次执行如下 SQL 语句:
1 | BEGIN TRANSACTION; |
可以发现,与文章形成一对多关系的评论以及与文章形成多对多关系的标签,都会被创建,并且 GORM 会维护其关联关系,而且这些操作全部在一个事务下完成。
此外,前文介绍的 Save 方法不仅能够更新记录,实际上它还支持创建记录,当 Post 对象不存在主键 ID 时,Save 方法将会创建一条新的记录:
1 | var post3 Post |
以上代码生成的 SQL 如下:
1 | BEGIN TRANSACTION; |
查询
可以使用如下方式,根据 Post 的 ID 查询与之关联的 Comments:
1 | var ( |
注意⚠️:传递给
Association方法的参数是Comments,即在Post模型中定义的字段,而非评论的模型名Comment。这点一定不要搞错了,不然执行 SQL 时会报错。
Post 是源模型,主键 ID 不能为空。Association 方法指定关联字段名,在 Post 模型中关联的评论使用 Comments 表示。最后使用 Find 方法来查询关联的评论。
在查询 Post 时,我们可以预加载与之关联的 Comments:
1 | post2 := Post{} |
我们可以像往常一样使用 First 方法查询一条 Post 记录,同时搭配使用 Preload 方法来指定预加载的关联字段名,这样在查询 Post 记录时,会将关联字段表的记录全部查询出来,并赋值给关联字段。
以上代码将执行如下 SQL:
1 | BEGIN TRANSACTION; |
GORM 通过多条 SQL 语句查询出所有关联记录,并且将关联 Comments 和 Tags 分别赋值给 Post 模型对应字段。
当遇到多表查询时,我们通常还会使用 JOIN 来连接多张表:
1 | type PostComment struct { |
使用 Select 方法来指定需要查询的字段,使用 Joins 方法来实现 JOIN 功能,最终使用 Scan 方法可以将查询结果扫描到 postComment 对象中。
针对一对多关联关系,Joins 方法同样支持预加载:
1 | var comments2 []*Comment |
JOIN 功能的预加载无需显式使用 Preload 来指明,只需要在 Joins 方法中指明一对多关系中一这一端模型 Post 即可,使用 Find 查询 Comment 记录。
根据生成的 SQL 可以发现查询主表为 comment,副表为 post。并且副表的字段都被重命名为 模型名__字段名 的格式,如 Post__title(题外话:如果你使用过 Python 的 Django ORM 框架,那么对这个双下划线命名字段的做法应该有种似曾相识的感觉)。
更新
同讲解单表更新时一样,我们需要先查询出一条记录,用来演示更新操作:
1 | var post Post |
可以使用如下方法替换 Post 关联的 Comments:
1 | comment := Comment{ |
仍然使用 Association 方法指定 Post 关联的 Comments,Replace 方法用来完成替换操作。
这里要注意,Replace 方法返回结果不再是 *gorm.DB 对象,而是直接返回 error。
生成 SQL 如下:
1 | BEGIN TRANSACTION; |
删除
使用 Delete 删除文章表时,不会删除关联表的数据:
1 | var post Post |
对于存在关联关系的记录,删除时默认同样采用 UPDATE 操作,且不影响关联数据。
如果想要在删除评论时,顺便删除与文章的关联关系,可以使用 Association 方法:
1 | // UPDATE `comment` SET `post_id`=NULL WHERE `comment`.`post_id` = 6 AND `comment`.`id` IN (NULL) AND `comment`.`deleted_at` IS NULL |
事务
GORM 提供了对事务的支持,这在复杂的业务逻辑中是必要的。
要在事务中执行一系列操作,可以使用 Transaction 方法实现:
1 | func TransactionPost(db *gorm.DB) error { |
在 Transaction 方法内部的代码,都将在一个事务中被处理。Transaction 方法接收一个函数,其参数为 tx *gorm.DB,事务中所有数据库的操作,都应该使用这个 tx 而非 db。
在执行事务的函数中,返回任何错误,整个事务都将被回滚,返回 nil 则事务被提交。
除了使用 Transaction 自动管理事务,我们还可以手动管理事务:
1 | func TransactionPostWithManually(db *gorm.DB) error { |
db.Begin() 用于开启事务,并返回 tx,稍后的事务操作都应使用这个 tx 对象。如果在处理事务的过程中遇到错误,可以使用 tx.Rollback() 回滚事务,如果没有问题,最终可以使用 tx.Commit() 提交事务。
注意:手动事务,事务一旦开始,你就应该使用
tx处理数据库操作。
钩子
GORM 还支持 Hook 功能,Hook 是在创建、查询、更新、删除等操作之前、之后调用的函数,用来管理对象的生命周期。
钩子方法的函数签名为 func(*gorm.DB) error,比如以下钩子函数在创建操作之前触发:
1 | func (u *User) BeforeCreate(tx *gorm.DB) (err error) { |
比如我们为 User 模型定义 BeforeCreate 钩子,这样在创建 User 对象前,GORM 会自动调用此函数,完成为 User 对象创建 UUID 以及用户名合法性验证功能。
GORM 支持的钩子函数以及执行时机如下:
| 钩子函数 | 执行时机 |
|---|---|
| BeforeSave | 调用 Save 前 |
| AfterSave | 调用 Save 后 |
| BeforeCreate | 插入记录前 |
| AfterCreate | 插入记录后 |
| BeforeUpdate | 更新记录前 |
| AfterUpdate | 更新记录后 |
| BeforeDelete | 删除记录前 |
| AfterDelete | 删除记录后 |
| AfterFind | 查询记录后 |
原生 SQL
虽然我们使用 ORM 框架往往是为了将原生 SQL 的编写转为面向对象编程,不过对原生 SQL 的支持是一款 ORM 框架必备的功能。
可以使用 Raw 方法执行原生查询 SQL,并将结果 Scan 到模型中:
1 | var userRes UserResult |
原生 SQL 同样支持使用表达式:
1 | var sumage int |
此外,我们还可以使用 Exec 执行任意原生 SQL:
1 | db.Exec("UPDATE user SET age = ? WHERE id IN ?", 18, []int64{1, 2}) |
使用 Exec 无法拿到执行结果,可以用来对表进行操作,比如增加、删除表等。
编写 SQL 时支持使用 @name 语法命名参数:
1 | var post Post |
使用 DryRun 模式可以直接拿到由 GORM 生成的原生 SQL,而不执行,方便后续使用:
1 | var user User |
DryRun 模式可以翻译为空跑,意思是不执行真正的 SQL,这在调试时非常有用。
调试
GORM 常用功能我们已经基本讲解完成了,最后再来介绍下在日常开发中,遇到问题如何进行调试。
GORM 调试方法我总结了如下 5 点:
- 全局开启日志
还记得在连接数据库时 gorm.Open 方法的第二个参数吗,我们当时传递了一个空配置 &gorm.Config{},这个可选的参数可以改变 GORM 的一些默认功能配置,比如我们可以设置日志级别为 Info,这样就能够在控制台打印所有执行的 SQL 语句:
1 | db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{ |
- 打印慢查询 SQL
有时候某段 ORM 代码执行很慢,我们可以通过开启慢查询日志,来检测 SQL 中的慢查询语句:
1 | func ConnectMySQL(host, port, user, pass, dbname string) (*gorm.DB, error) { |
- 打印指定 SQL
使用 Debug 能够打印当前 ORM 语句执行的 SQL:
1 | db.Debug().First(&User{}) |
- 全局开启 DryRun 模型
在连接数据库时,我们可以全局开启「空跑」模式:
1 | db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{ |
开启 DryRun 模型后,任何 SQL 语句都不会真正执行,方便测试。
- 局部开启 DryRun 模型
在当前 Session 中局部开启「空跑」模型,可以在不执行操作的情况下生成 SQL 及其参数,用于准备或测试生成的 SQL:
1 | var user User |
总结
本文对 Go 语言中最流行的 ORM 框架 GORM 进行了讲解,介绍了如何编写模型,如何连接数据库,以及最常使用的 CRUD 操作。并且还对关联表中的一对多、多对多两种关联关系操作进行了讲解。我们还介绍了必不可少的功能「事务」,GORM 还提供了钩子函数方便我们在 CRUD 操作前后插入一些自定义逻辑。最后对如何使用原生 SQL 以及如何调试也进行了介绍。
只要你原生 SQL 基础扎实,ORM 框架学习起来并不会太费力,并且我们还有各种调试方式来打印 GORM 所生成的 SQL,方便排查问题。
由于文章篇幅所限,这里只介绍了 GORM 常用功能,不过也基本能够覆盖日常开发中多数场景。更多高级功能如自定义 Logger、读写分离、从数据库表反向生成模型等操作,可以参考官方文档进行学习。
本文完整代码示例我放在了 GitHub 上,欢迎点击查看。
希望此文能对你有所帮助。
联系我
- 微信:jianghushinian
- 邮箱:jianghushinian007@outlook.com
- 博客地址:https://jianghushinian.cn/
参考