此文为《用 Python 撸一个 Web 服务器》系列教程的一个补充,这个系列教程介绍了如何使用 Python 内置的 socket 库实现一个简易版的 Web 服务器。
之所以写这篇文章,是因为我发现很多人并不清楚 HTTP 客户端的概念,以为只有浏览器才叫 HTTP 客户端。事实上并非如此,我们在 Web 开发中常见的 Postman、爬虫程序、curl 命令行工具 等,这些都可以称为 HTTP 客户端。
服务器程序示例
这里以一个 Hello World 程序来作为示例服务器,实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
import socket
import threading
def process_connection(client):
"""处理客户端连接"""
data = b''
while True:
chunk = client.recv(1024)
data += chunk
if len(chunk) < 1024:
break
print(f'data: {data}')
client.sendall(b'HTTP/1.1 200 OK\r\nContent-Type: text/html\r\n\r\n<h1>Hello World</h1>')
client.close()
def main():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(('127.0.0.1', 8000))
sock.listen(5)
while True:
client, addr = sock.accept()
print(f'client type: {type(client)}\naddr: {addr}')
t = threading.Thread(target=process_connection, args=(client,))
t.start()
if __name__ == '__main__':
main()
|
服务器端程序不做过多解释,如有不明白的地方可以参考 用 Python 撸一个 Web 服务器-第2章:Hello-World 一节。
极简客户端
知道了如何用 socket 库实现服务器端程序,那么理解客户端程序的实现就非常容易了。客户端程序代码实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect(('127.0.0.1', 8000))
sock.send(b'GET / HTTP/1.1\r\nHost: 127.0.0.1:8000\r\n\r\n')
data = b''
while True:
chunk = sock.recv(1024)
data += chunk
if len(chunk) < 1024:
break
print(data)
sock.close()
|
相对来说客户端程序要简单一些,创建 socket 对象的代码与服务器端程序并无差别,客户端 socket 对象根据 IP 和端口来连接指定的服务器,建立好连接后就可以发送数据了,这里根据 HTTP 协议构造了一个针对 / URL 路径的 GET 请求,为了简单起见,请求头中仅携带了 HTTP 协议规定的必传字段 Host,请求发送成功后便可以接收服务器端响应,最后别忘了关闭 socket连接。
仅用几行代码,我们就实现了一个极简的 HTTP 客户端程序,接下来对其进行测试。
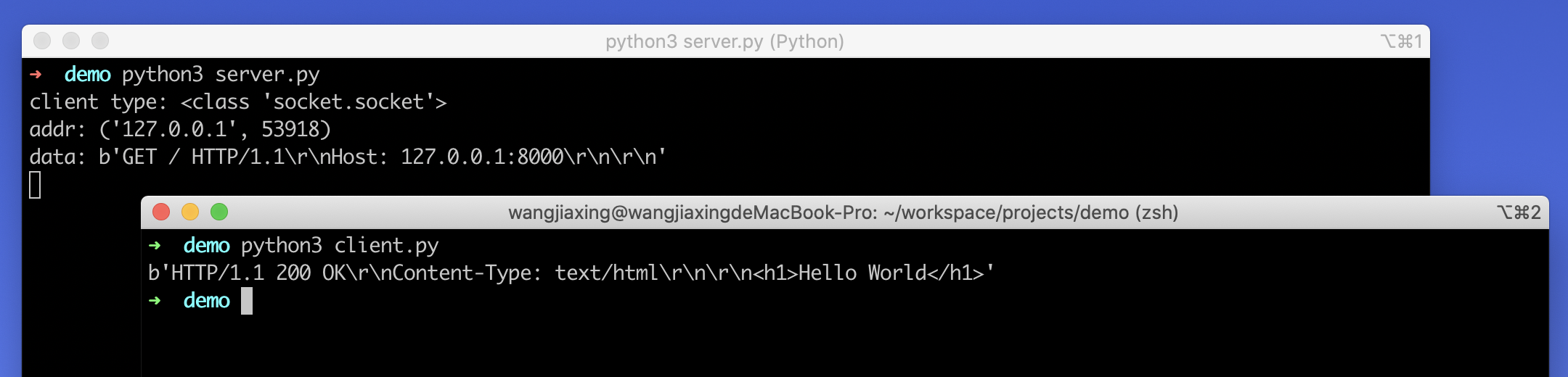
首先在终端中使用 Python 运行服务器端程序:python3 server.py。然后在另一个终端中使用 Python 运行客户端程序:python3 client.py。
可以看到客户端打印结果如下:
1
| b'HTTP/1.1 200 OK\r\nContent-Type: text/html\r\n\r\n<h1>Hello World</h1>'
|
以上,我们实现了一个极简的 HTTP 客户端。
参考 requests 实现客户端
用 Python 写过爬虫的同学,一定听说或使用过 requests 库,以下是使用 requests 访问 Hello World 服务端程序的示例代码:
1
2
3
4
5
6
7
8
9
10
|
import requests
response = requests.request('GET', 'http://127.0.0.1:8000/')
print(response.status_code)
print('--------------------')
print(response.headers)
print('--------------------')
print(response.text)
|
在终端中使用 python3 demo_requests.py 运行此程序,将打印如下结果:
1
2
3
4
5
| 200
--------------------
{'Content-Type': 'text/html'}
--------------------
<h1>Hello World</h1>
|
接下来修改我们上面实现的极简 HTTP 客户端程序,使其能够支持 response.status_code、response.headers 和 response.text功能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
import socket
from urllib.parse import urlparse
class HTTPClient(object):
"""HTTP 客户端"""
def __init__(self):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.status_code = 200
self.headers = {}
self.text = ''
def __del__(self):
self.sock.close()
def connect(self, ip, port):
"""建立连接"""
self.sock.connect((ip, port))
def request(self, method, url):
"""请求"""
parse_result = urlparse(url)
ip = parse_result.hostname
port = parse_result.port or 80
host = parse_result.netloc
path = parse_result.path
self.connect(ip, port)
send_data = f'{method} {path} HTTP/1.1\r\nHost: {host}\r\n\r\n'.encode('utf-8')
self.sock.send(send_data)
data = self.recv_data()
self.parse_data(data)
def recv_data(self):
"""接收数据"""
data = b''
while True:
chunk = self.sock.recv(1024)
data += chunk
if len(chunk) < 1024:
break
return data.decode('utf-8')
def parse_data(self, data):
"""解析数据"""
header, self.text = data.split('\r\n\r\n', 1)
status_line, header = header.split('\r\n', 1)
for item in header.split('\r\n'):
k, v = item.split(': ')
self.headers[k] = v
self.status_code = status_line.split(' ')[1]
if __name__ == '__main__':
client = HTTPClient()
client.request('GET', 'http://127.0.0.1:8000/')
print(client.status_code)
print('--------------------')
print(client.headers)
print('--------------------')
print(client.text)
|
代码实现比较简单,我写了较为详细的注释,相信你能够看懂。其中使用了内置函数 urlparse ,此函数能够根据 URL 格式规则将 URL 拆分成多个部分。
在终端中使用 python3 client.py 运行此程序,打印结果与使用 requests 的结果完全相同。
1
2
3
4
5
| 200
--------------------
{'Content-Type': 'text/html'}
--------------------
<h1>Hello World</h1>
|
仅用几十行代码,我们就实现了一个简易版的 HTTP 客户端程序,并且还实现了类似 requests 库的功能。
接下来你可以尝试用它去访问现实世界中真实的 URL,比如访问 http://httpbin.org/get,看看打印结果如何。
P.S.
Web 开发本质是围绕着 HTTP 协议进行的,HTTP 协议是 Web 开发的基石。所以对于何为 HTTP 服务端、何为 HTTP 客户端的概念不够清晰的话,实际上都是对 HTTP 协议不够理解。
最后,给大家留一道作业题,实现 requests 库的 response.json() 方法。